
Baidu Spider上一次升级还要追溯到2010年。
那个时候,中国互联网资源急剧扩张,从百亿扩大到千亿规模,因而百度spider系统进行了重构,从单机互联转变为分布式计算系统。
但是有一个很大的缺点:延时严重!
而此次Baidu Spider重构是把当前离线、全量计算为主的系统,改造成实时、增量计算的全实时调度系统,万亿规模的数据进行实时读写,可以收录90%的网页,速度提升80%!
一张图以蔽之:
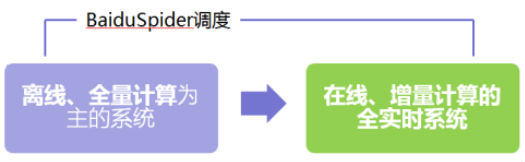
一、链接发现方面
如今百度sipder每天发现的新链接在500亿左右的量级,而在百度站长平台提交链接是其中最为高效的,特此,工程师提醒站长不要过度提交链接,尤其是低质链接,这样才能达到更好更及时的收录效果。
二、链接抓取方面
策略上,开发了更强大的机器学习模型,来进行链接的质量预测,对库中所有的链接进行全局排序,对有价值链接的召回率提高95%!
架构上,计算性能的强劲提升,对每天新增的数百亿模块的链接,完成实时计算,延时不到1秒;开发了更强大的存储系统,面对万亿规模的数据做到实时读写。
三、时效性页面方面
中长尾站的福音!针对时效性资源,从原来的优先对新浪、网易等大新闻站进行抓取,扩大到覆盖全网的新闻、博客、论坛等站点进行快速抓取,大小站都能优待。
打破老的平稳抓取模型,采用按需抓取机制,对有时效性新资源,做到秒级抓取。
目前,每天收录的时效性资源规模,扩大到原来的3倍,达到近1亿量级!
四、死链方面
全新的死链识别模型,能识别各种协议死链、内容死链、跳转死链等低质网页。
其中无效低质网页(如被黑),通过百度站长平台提交,可加快检索屏蔽的过程。
五、建库方面
索引展现时效性提升,原来是10天左右,现在提升40%~80%不等!




